by Ryan Blue

I’m excited to announce that, as of this morning, we have opened up sign-ups for Tabular. If you can hardly sit still because you’re so eager to sign up, go create a free account! Then come back for a quick tour.
It’s amazing to be at this point. It’s been more than 7 years since Dan and I met up for coffee to talk about a job at Netflix — and ended up spending the entire time talking about data infrastructure challenges. That was a pivotal conversation because we set out a vision for our ideal data architecture that has stuck with us ever since (plus, I joined Netflix).
A couple years later, we saw those early ideas start coming to life when we created Apache Iceberg. We finally had a solid foundation to build on. And today we’re taking another step by releasing Tabular. Tabular is our version of the data platform we dreamt up over coffee, but built with the best practices and lessons learned in the meantime by running the v1 platform at Netflix.
Best practices are hard to come by other than through lived experience — that is, mistakes. Infrastructure choices are often made at the wrong time, and by the time you understand what you should have done you’re well beyond the point of no return. Tabular helps you avoid those problems.
What is Tabular?
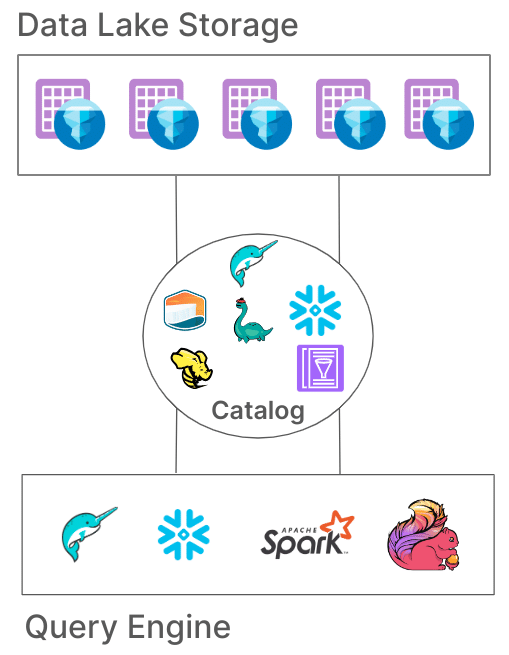
Tabular is everything you need in your data platform — except for compute. We think of Tabular as the storage half of a data warehouse that you can easily connect to your tool of choice, from Python notebooks to full query engines. Tabular is a managed metastore catalog integrated with role-based access controls and a swarm of automated services.
The goal of this architecture is to enable you. First, to enable you to use the right tool for what you need to do. Tabular already supports Trino, Spark, Flink, and PyIceberg (DuckDB!) as well as read-only connectivity in Snowflake, Starburst, and AWS Athena. We’re working hard to expand the set of engines and partners that are integrated with the platform, and have made it simple to securely work with Tabular tables.
Second, Tabular’s goal is to enable you to focus on your business problems, not infrastructure. To do that, we’ve designed around core principles for a product that is:
- Simple — Tabular bundles all of the background services you need, without the headache of setting up separate projects, wiring them together, testing, and debugging. A complete platform from the start prevents problems, like wishing you’d had S3 access logs flowing.
- Secure — Tabular locks down your data, not individual tools or engines. Your RBAC policies are consistently enforced, even in Spark and Python where permissions are notoriously difficult.
- Automated — Tabular runs services that keep your tables healthy and performant.
The promise of automation is what excited us and drove us to build Iceberg and unblock a platform like Tabular. Tabular automates boring maintenance you never want to think about again, like cleaning up old versions or removing unreferenced files. It handles simple tasks, like importing CSV and JSON files as they land in S3. It also optimizes tables by recommending settings to boost performance or reduce data volume and will actively fix tables to save on compute or storage costs.
Over time, Tabular will continue to grow more and more capable, but we’ve already shown that the platform’s early automatic optimization can save one customer $2m over two years in S3 costs alone.
And, of course, Tabular stores your data in your own AWS bucket as 100% open-source Apache Iceberg tables so there’s no lock-in.
Let us know what you think!
We’re thrilled to open Tabular to public signups today and to share the platform we’ve been building toward for years. It’s still early for Tabular, but we think that there is already tremendous value in this platform: it’s painless, it’s secure, and it saves you time.
Please sign up and check it out! After that, we’d love to get your feedback. Just reach out in #vendor-tabular in the Apache Iceberg Slack community to let us know what you think and what you’d like to see next.
Lastly, thanks to the amazing Tabular team for getting us here!
Originally published March 1, 2023, on tabular.io